De documentación y capturas al .feature: IA local con Llama 3.2 + Llava
19 May 2025
En este artículo te muestro cómo montar un flujo completo de generación de escenarios .feature (Gherkin) y casos de uso a partir de requisitos funcionales y capturas de pantalla, todo ejecutado 100% en local, sin necesidad de enviar datos sensibles a servicios externos. Esto elimina las barreras legales y técnicas que muchas empresas ponen cuando se quiere usar IA con datos internos.
Gracias a herramientas como Ollama, puedes tener modelos LLM como Llama 3.2 (para texto) y Llava (para visión) corriendo directamente en tu equipo, sin pagar APIs, sin exponer datos, sin depender de internet…
Este primer post no solo sirve como ejemplo práctico para profesionales de QA, sino como guía de cómo desplegar e integrar modelos locales de forma sencilla. Es el primer paso de una serie en la que exploraremos cómo pasar de requisitos a código de automatización real generado por IA.
Si trabajas en QA, desarrollo o estás explorando cómo usar IA sin comprometer la privacidad de tus proyectos, este artículo es para ti.
Modelos que se utilizarán:
Tarea Modelo Peso Q4 RAM real Texto → Gherkin Llama 3.2 4.4 GB 6–8 GB Imagen + texto → Gherkin Llava 4.7 GB 7-8 GB
1. ¿Por qué ejecutar la IA en local?
- Privacidad y cumplimiento Los requisitos y los mock-ups nunca salen de tu equipo, así que no hay riesgo de que queden guardados en los registros de un servicio externo. Puedes incluso ejecutarlos sin conexión a internet.
- Coste cero & offline Sin cuotas ni límites de API. No pagas tokens por petición, no temes sobrecostes y puedes realizar tantas iteraciones como quieras mientras ajustas el prompt.
- Iteración rápida Modificas prompts, re‑corres, comparas… sin esperar cola externa.
- Independencia Si mañana cambian precios o políticas de una API, tu flujo sigue igual. Además, puedes afinar el modelo con ejemplos propios sin enviarlos a nadie.
2. Setup
En esta sección vamos a preparar el entorno necesario para ejecutar nuestro generador de escenarios .feature usando modelos LLM locales.
¿Qué es Ollama?
Ollama es una herramienta que permite ejecutar modelos de lenguaje (LLM) de forma local en tu equipo, sin necesidad de depender de servicios en la nube. Ofrece multitud de módulos de diferentes tamaños y propósitos.
2.1. Instalar Ollama
Dependiendo de tu sistema operativo, puedes instalar Ollama de dos formas:
Opción 1. Instalación rápida por terminal
# Para macOS
brew install ollama
# Para Windows
winget install Ollama.Ollama
# Para Linux
curl -fsSL https://ollama.com/install.sh | sh
Nota: Necesitarás tener instalado
brew(macOS),winget(Windows) ocurl(Linux). Si no los tienes, consulta su documentación correspondiente.
Opción 2. Instalación manual desde su web
También puedes instalar Ollama como cualquier otro programa, descargándolo directamente desde su web oficial: Descargar Ollama
Solo tienes que ir a la sección de instalación, descargar el instalador correspondiente a tu sistema operativo y seguir los pasos habituales.
2.2. Iniciar el servidor de Ollama
Una vez instalado Ollama, es necesario arrancar el servidor local, que es el encargado de gestionar los modelos y responder a nuestras peticiones.
Si lo instalaste desde la terminal
Ejecuta el siguiente comando para lanzar el servidor en segundo plano:
ollama serve &
Esto dejará el servidor corriendo y listo para recibir peticiones desde otros scripts o herramientas.
Si lo instalaste manualmente desde la web
Simplemente abre la aplicación de Ollama como cualquier otro programa en tu sistema. Esto pondrá en marcha el servidor de forma automática.
Importante: A partir de este punto, todos los pasos siguientes funcionarán exactamente igual, independientemente del método de instalación que hayas elegido.
2.3. Descargar modelos LLM
Una vez iniciado el servidor, vamos a descargar los modelos que utilizaremos para generar nuestros escenarios .feature y para describir interfaces a partir de imágenes:
ollama pull llama3.2
ollama pull llava
¿Por qué estos modelos?
llama3.2: modelo de texto optimizado para tareas complejas como generación de código, razonamiento y QA avanzado. Lo utilizaremos para generar escenarios en lenguaje Gherkin. Aunque es un modelo grande para el uso puntual que haremos aquí, lo descargamos desde el principio para tenerlo disponible en local y reutilizarlo más adelante, por ejemplo, para generar código de automatización con Selenium en futuros proyectos.llava: modelo multimodal que puede interpretar tanto texto como imágenes. Lo utilizamos específicamente para extraer descripciones detalladas de interfaces a partir de capturas de pantalla. Su capacidad de visión lo hace ideal para este tipo de tareas sin depender de soluciones en la nube.
2.4. Clonar el repositorio del proyecto
Clonamos el proyecto base que contiene toda la lógica para interactuar con los modelos, pasarles los prompts adecuados y generar archivos .feature automáticamente.
git clone https://github.com/abarragancosto/llm-feature-gen.git
cd llm-feature-gen
En este repositorio encontrarás:
- Scripts para lanzar peticiones a los modelos
- Templates de prompts optimizados
- Utilidades para guardar las salidas directamente como archivos
.feature
2.5. Crear entorno virtual e instalar dependencias
Creamos un entorno virtual para aislar las dependencias del proyecto:
python -m venv .venv && source .venv/bin/activate
Y luego instalamos todos los paquetes necesarios:
pip install -r requirements.txt
Esto incluye bibliotecas para interactuar con Ollama, procesar imágenes, manejar prompts, etc.
3. Ejecutar programa
Una vez descargados los modelos y arrancado el servidor de Ollama, ya puedes utilizar el script generate_features.py para generar automáticamente escenarios en formato Gherkin (.feature) o descripciones de casos de uso a partir de texto y, opcionalmente, imágenes de mock-up.
Argumentos disponibles
El script admite varios parámetros para personalizar la ejecución:
| Parámetro | Descripción |
|---|---|
requirements |
Ruta al archivo de requisitos (en formato .txt o .md). Obligatorio. |
-m, --mockup |
Ruta a una imagen de la interfaz si se desea usar un modelo con capacidad visual. (Opcional) |
-n, --num |
Número de escenarios o casos a generar (por defecto: 5). (Opcional) |
-o, --output |
Nombre del archivo de salida. Por defecto: output.feature. |
-f, --format |
Formato de salida: feature para Gherkin o txt para casos de uso en texto plano. Obligatorio |
--prompt-file |
Ruta a un archivo con prompt personalizado (opcional). |
3.1 Solo texto
Si solo tienes una descripción funcional (sin mock-up) y quieres generar escenarios en formato .feature, ejecuta:
python generate_features.py examples/requirements.txt -o login.feature
Esto usará el archivo examples/requirements.txt, generará 5 escenarios (valor por defecto) y los guardará en login.feature.
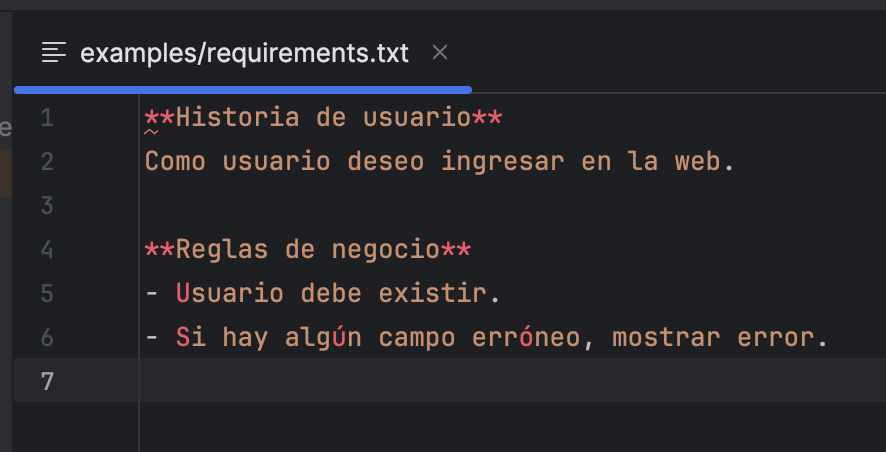
Como demostración del ejemplo, el fichero requirements.txt contiene lo siguiente:
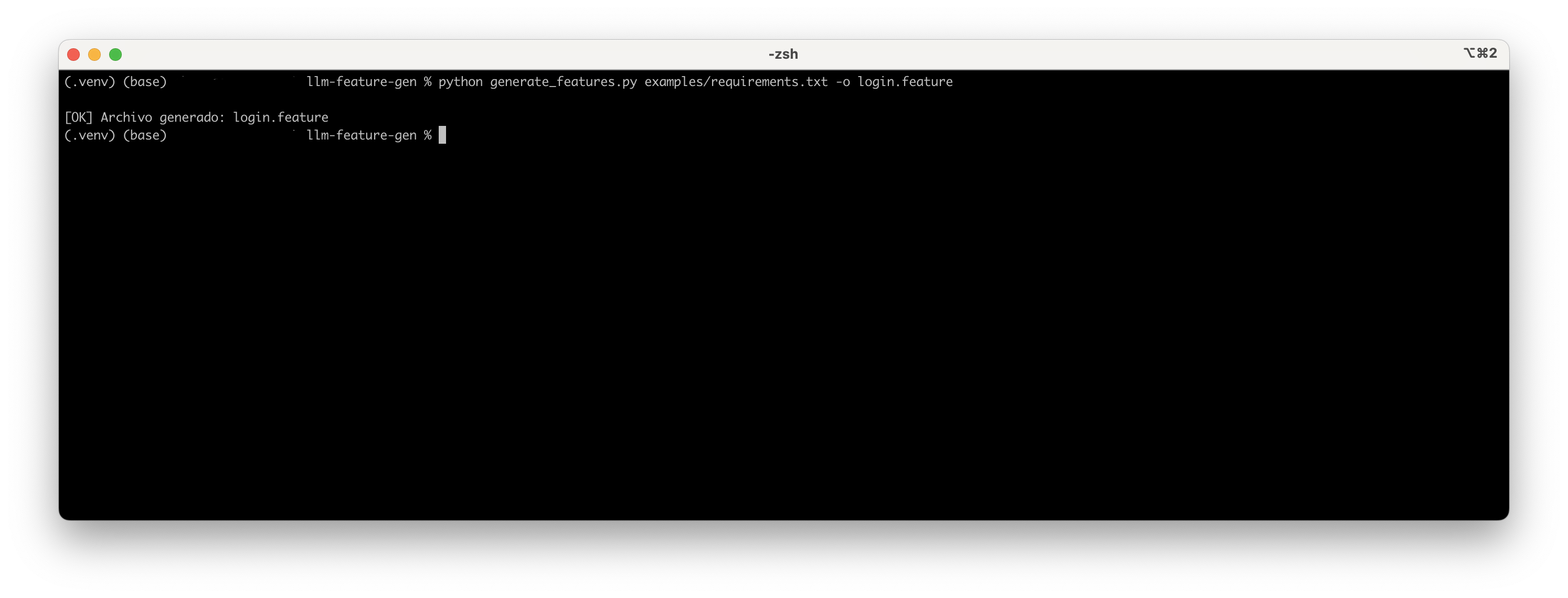
Una vez ejecutado, por consola nos saldrá:
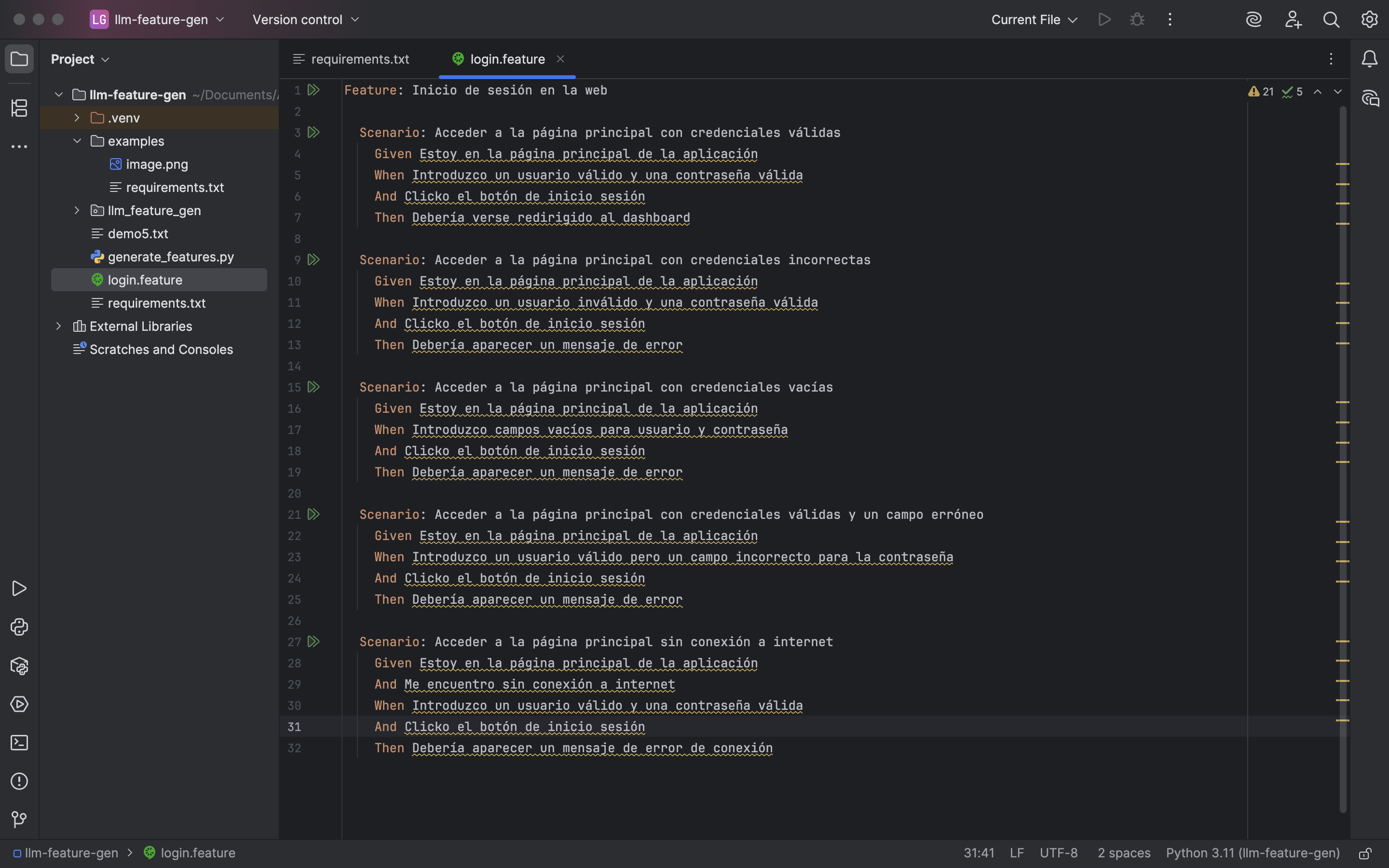
El resultado de la feature será:
3.2 Texto + mock‑up
Si además del archivo de requisitos tienes una imagen de la interfaz (mock-up), puedes añadirla para que el modelo la interprete y genere escenarios más ajustados visualmente:
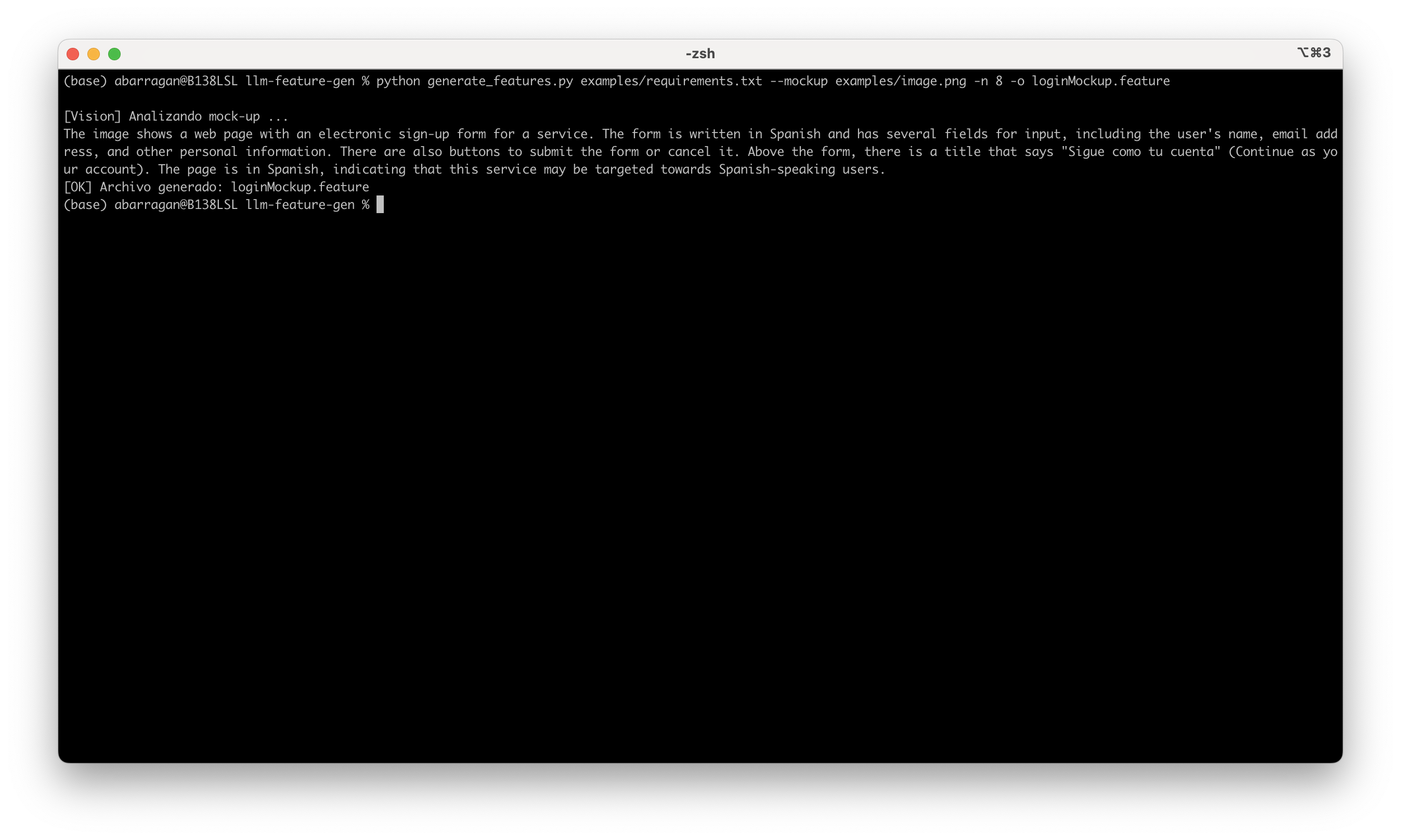
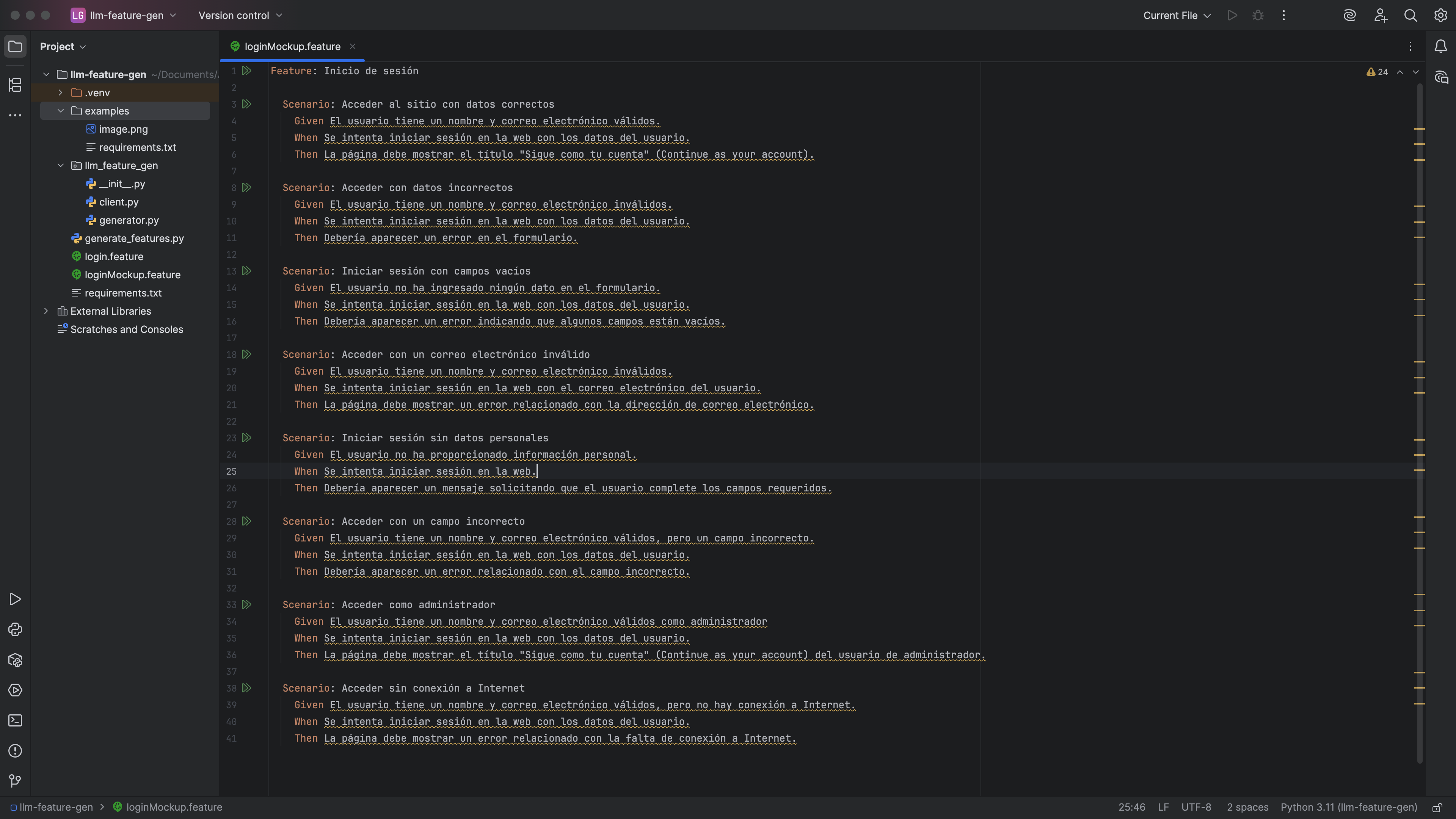
python generate_features.py examples/requirements.txt --mockup examples/image.png -n 8 -o loginMockup.feature
📌 Esto generará 8 escenarios combinando texto e imagen, y los guardará en loginMockup.feature.
La consola mostrará el resultado de la interpretación de imagen a texto:
El resultado de la feature sería:
Ejemplo con salida en texto plano
Si no quieres escenarios en Gherkin sino casos de uso en un txt, cambia el formato de salida con --format txt:
python generate_features.py examples/requirements.txt -f txt -o casos_uso.txt
Usar un prompt personalizado
Puedes utilizar tu propio archivo de prompt (por ejemplo, para adaptar el estilo o el idioma):
python generate_features.py examples/requirements.txt --prompt-file custom_prompt.txt
4. Comentarios finales
-
La revisión humana es clave: Aunque el uso de modelos LLM agiliza notablemente la generación de escenarios y casos de uso, no sustituye el criterio de un buen QA. Lo generado puede servir como punto de partida, inspiración o repaso de casos que podrían haberse pasado por alto, pero siempre debe haber una validación manual.
-
Versión ligera recomendada: Si
llavate resulta pesado en tu equipo, te recomiendo probar la versión optimizadallava:7b-v1.5-q4_0. Es la que he utilizado para las pruebas y ofrece un excelente equilibrio entre rendimiento y calidad. -
Objetivo de este post: Esta primera entrega ha sido una toma de contacto para mostrar cómo puedes trabajar con modelos LLM de forma local, sin depender de APIs externas, y generar
.featurefiles de forma automática a partir de requisitos. -
Lo realmente valioso: Más allá de automatizar la generación de archivos
.feature, lo importante aquí es mostrar que tener modelos potentes en tu máquina local es posible, gratuito y muy útil en flujos QA reales.
5. Próximos pasos
En próximos artículos, daremos un paso más: convertiremos estos archivos .feature en código Selenium (Java) utilizando IA, incluyendo estructuras Page Object y sugerencias de selectores automáticos.
Este flujo completo permitirá generar desde requisitos hasta pruebas automatizadas listas para ejecución, todo asistido por modelos LLM.
6. ¿Te animas a dar feedback?
¿Has probado este flujo? Me encantaría saber tu opinión:
- ¿Te ha resultado útil este post?
- ¿Te gustaría más profundidad técnica o que fuera más directo al grano?
- ¿Te interesa que detalle más las herramientas utilizadas?
- ¿Echas de menos más ejemplos o capturas?
Tu feedback me ayuda a mejorar cada contenido. ¡Gracias por llegar hasta aquí y ser parte de este experimento con LLMs en QA! 🙌